Large language models (LLMs) have unified diverse linguistic tasks within a single framework, yet such
unification remains unexplored in human motion generation. Existing methods are confined to isolated
tasks, limiting flexibility for free-form and omni-objective generation.
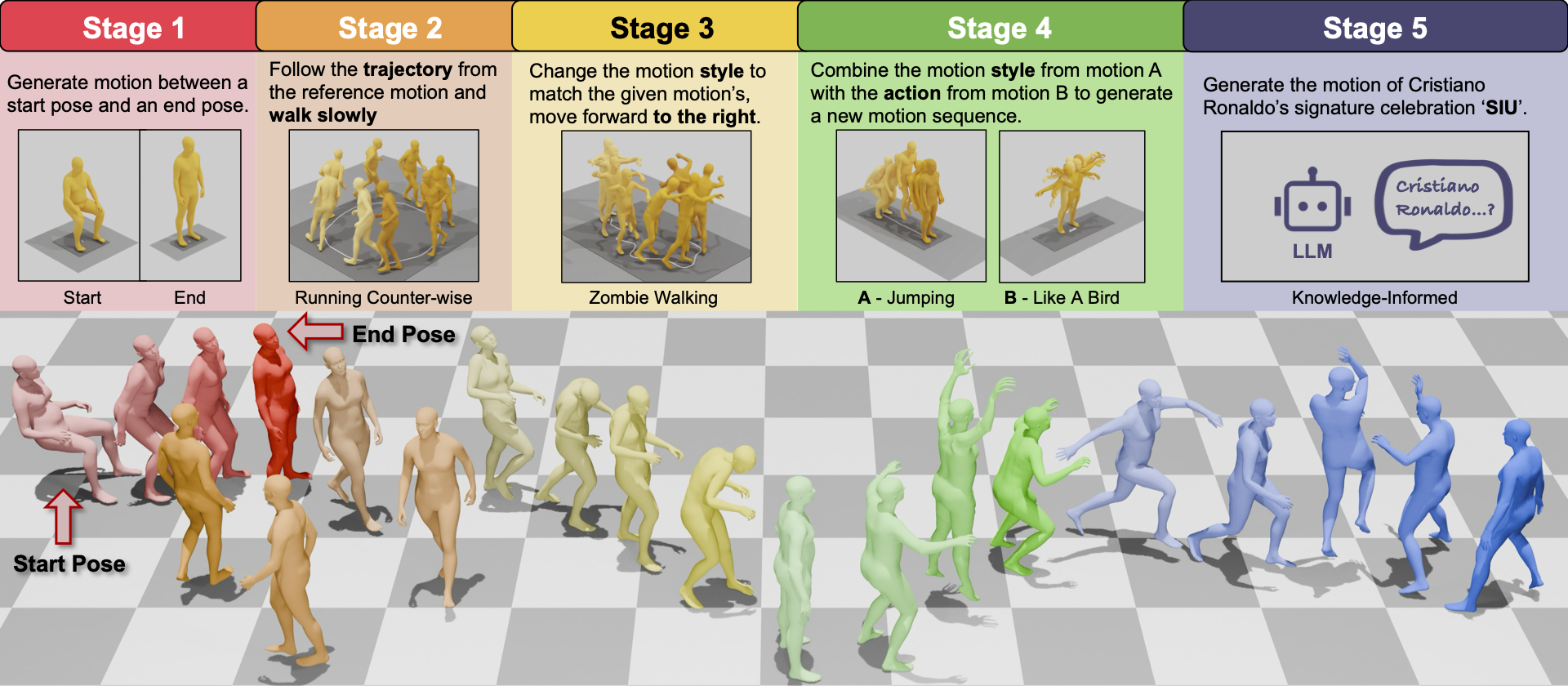
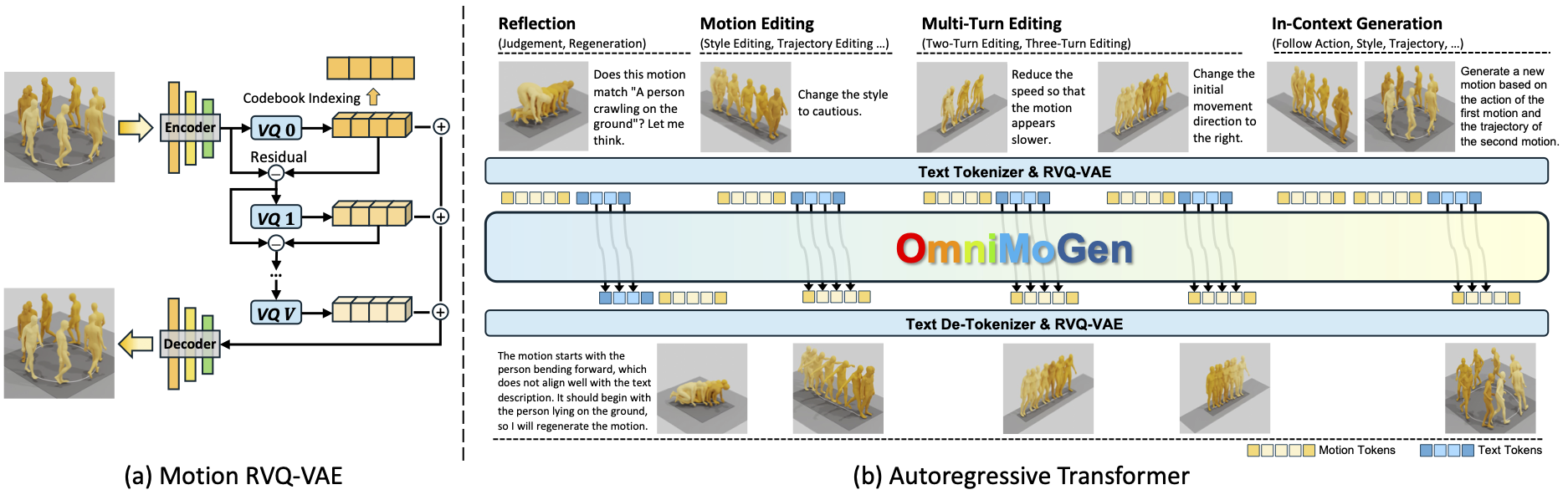
To address this, we propose OmniMoGen, a unified framework that enables versatile motion generation
through interleaved text-motion instructions. Built upon a concise RVQ-VAE and transformer architecture,
OmniMoGen supports end-to-end instruction-driven motion generation.
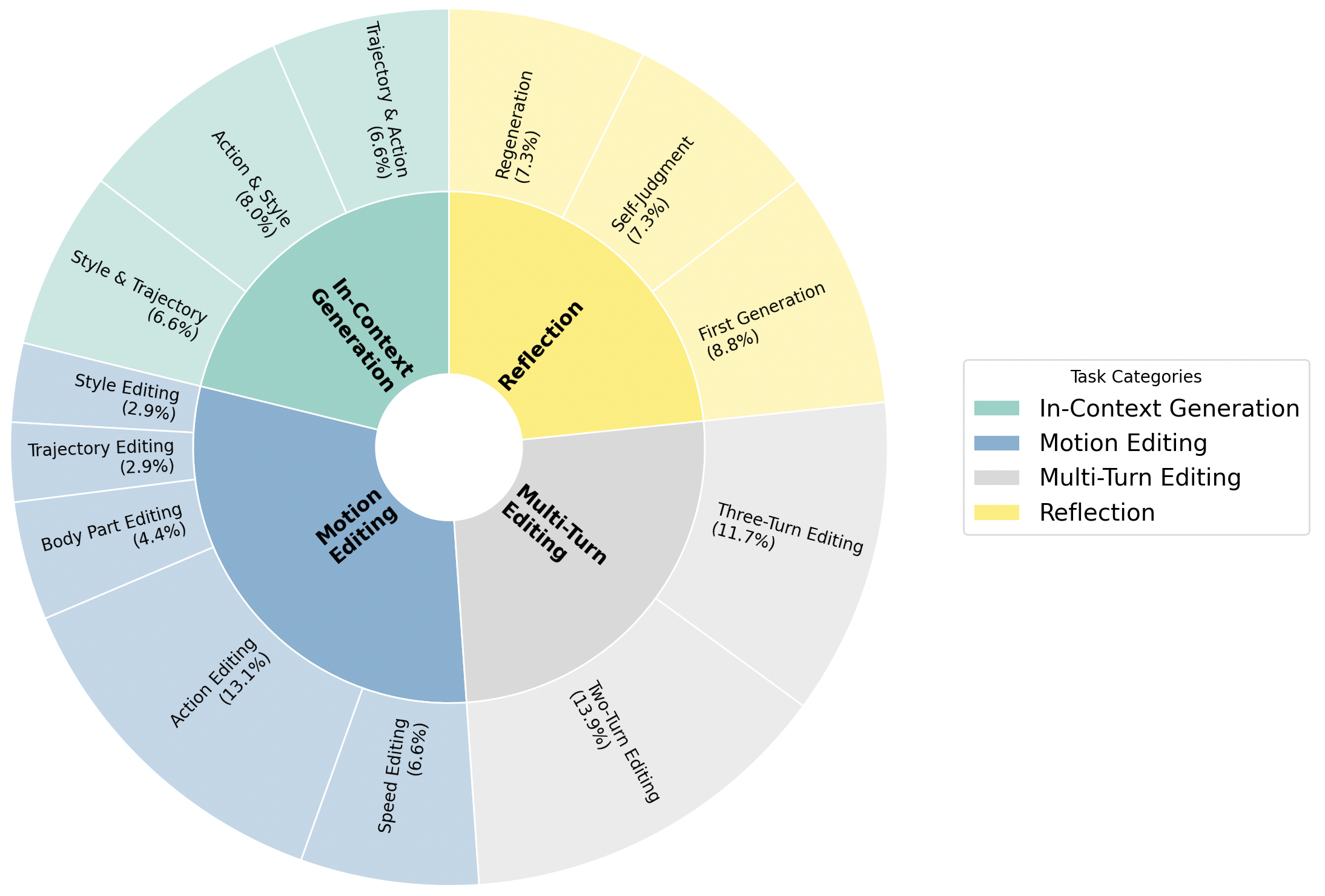
We construct X2Mo, a large-scale dataset of over 137K interleaved text-motion instructions, and
introduce AnyContext, a benchmark for evaluating interleaved motion generation. Experiments show
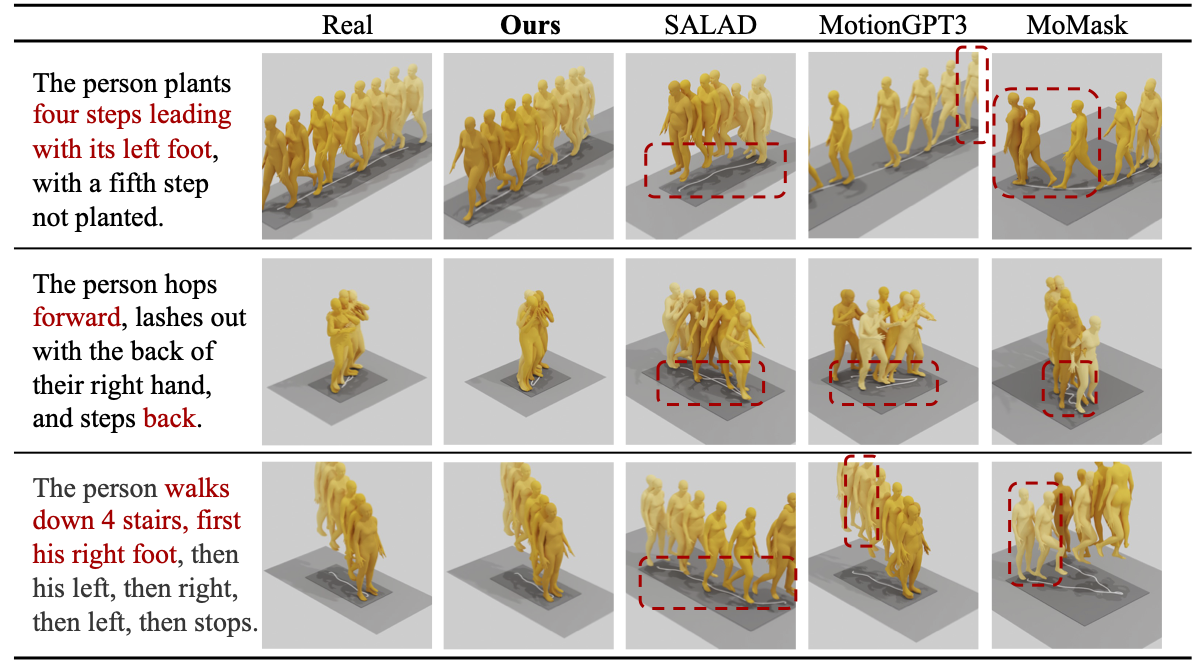
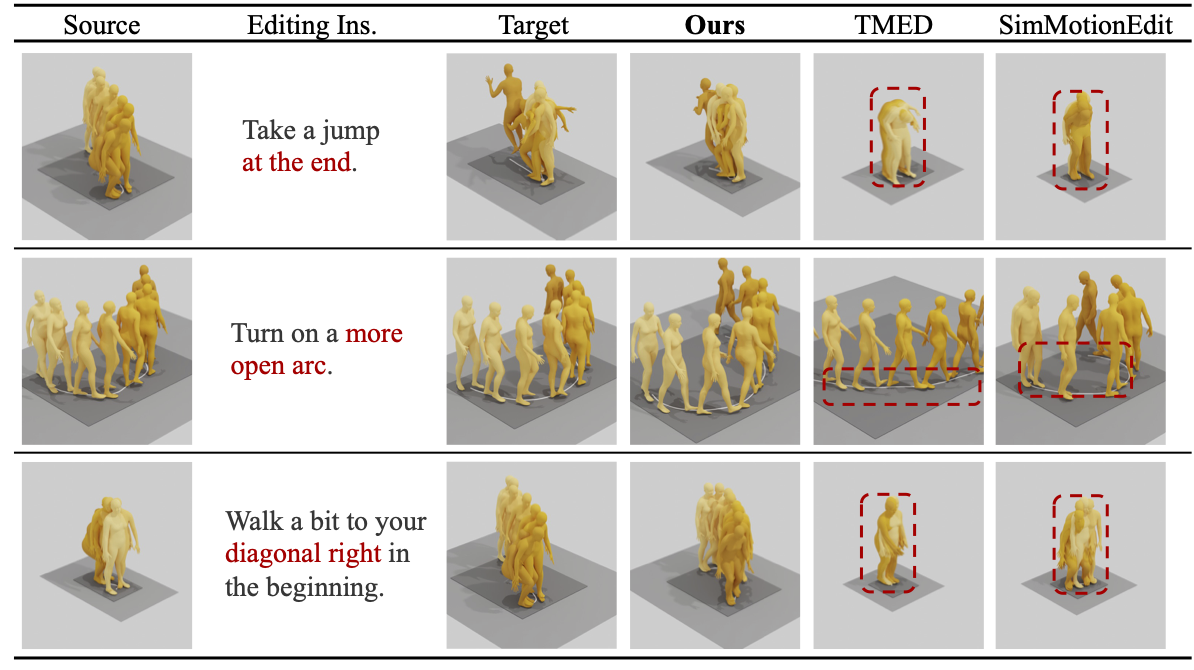
that OmniMoGen achieves state-of-the-art performance on text-to-motion, motion editing, and AnyContext,
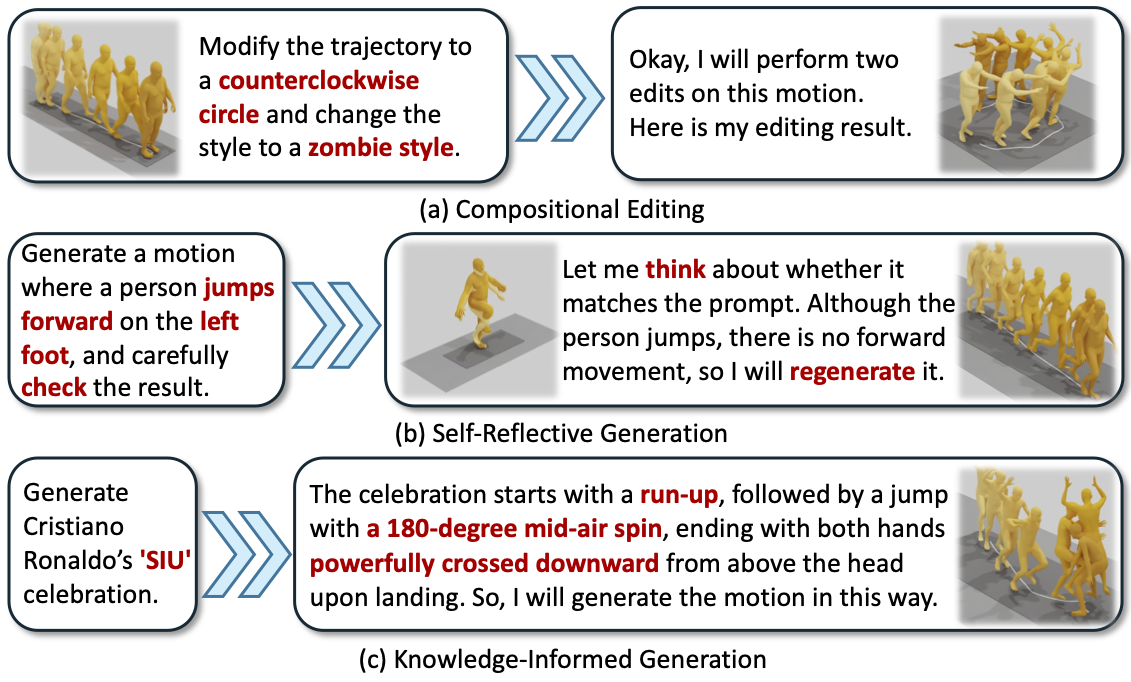
exhibiting emerging capabilities such as compositional editing, self-reflective generation, and
knowledge-informed generation. These results mark a step toward the next intelligent motion generation.